![]()
Although not that controversial, there is always the issue: “Should we just answer the question, or opt for a more comprehensive treatment of the issue to which the question is associated?” There has been some discussion about this here and on other SE meta-sites also, and various opinions have been registered – although, as I said, it is not an issue that creates hot debates (and this is perhaps why most of the opinions were aired in comments or in the context of an answer to a meta-post with a different focus).
My intention here is to provide a tiny bit of statistical evidence that, “If we opt for a more comprehensive treatment of the issue to which the question is associated, we are also being more helpful to the OP and to the OP’s specific question – according to the OP.”
Naturally I expect that the true statisticians in this site will be able to tear my argument apart (always in good spirit and with good intentions of course) – but this is one of my secret motives for this post: to see applied statistics at work, from the point of view of judging the degree to which postulated conclusions are indeed supported by the statistical evidence, even tentatively.
What I will do is to examine the relation between upvotes per answer and accepted/non-accepted answers, or “green/ungreen” answers. At least in theory, the number of upvotes, at least conditional on the popularity of the issue answered, is a rough indication of the general quality of the answer, while the green mark indicates strictly the opinion of the OP, who, having a specific question in mind looks for an answer to his specific question, and may find a more general treatment to be an obstacle rather than helpful.
So one could argue that there may be a conflict here: the more focused an answer is, the more helpful will be to the OP (and so the more the chances that it will get the green check), but the less interesting will be for the broader community (and so it will have less chances of being highly upvoted).
So here is what I’ve done: I examined myself as an answerer here on CV. I have 379 answers currently. My answers usually get few upvotes: only 14% of them have got 5 or more, and there are only 7 answers that got 10 upvotes or more. Partly, one could attribute this to the fact that it appears that I do tend to answer questions that do not interest the majority of users here – but most probably it is also an indication that my answers are just “OK”.
Now, according to this query, I have the top accepted-answers-ratio (48%) among users that have 25% more, or less, answers than me [285 , 475]. This could be considered as evidence that I am good at getting the green mark. Following the previous conjecture, this could also contribute to the low-upvotes finding: I am answering narrowly, so I may be getting the green mark from the OP, but my answers do not excite the wider community.
Given these preliminary findings, let’s look at the counts, as well as the joint-marginal and conditional empirical relative frequencies here (rounded). I have separated the “upvote” space in three bins. The “one or less” bin seems a natural choice. I have used “5 or more”, just getting the idea from our network profiles, where shown are only answers with five or more upvotes. But it proved an interesting binning.
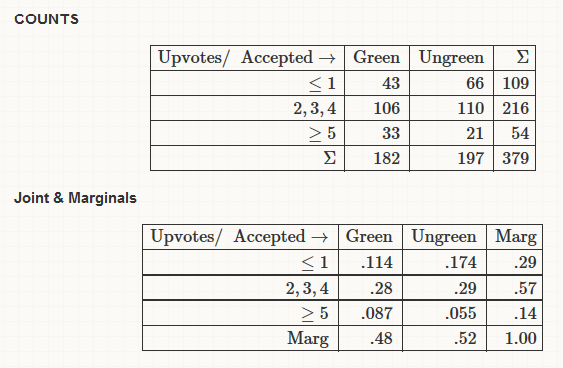
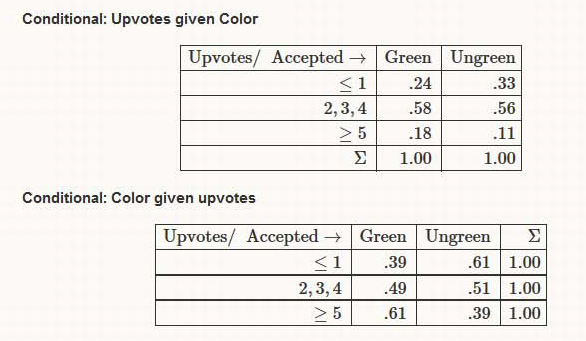
The above seem to indicate that color and upvotes are uninformative for each other regarding the middle of the distributions involved, but they are informative for the two tails. Especially the 2nd conditional table, where an apparently clear positive association emerges: knowing that an answer has got 5 or more upvotes visibly increases the chances that it is also a green one, compared to the marginal “probability” of being green.
To me, this is evidence that answering in a more broad fashion is more beneficial both for the users of CV in general, but also for the OP. And I believe this is strengthened by the fact that I tend not to answer narrowly, but broadly, which means that we do not have to condition also on my “answering approach”. So “when my broad answers are liked by the community, they are more helpful to the OP also” (this last statement is just an example of the attempt to turn science into rhetoric).
But this is just one user, and not “representative” of the community, by his own words. One can understand that performing such kind of analysis on data related to other users has the danger of being considered indiscreet, and rightfully so. I am leaving it at that, and hope for some statistical discussion on the issue. Thanks for reading thus far.
Filed under viewpoints
Tagged: Accepted-answer, Answers
Subscribe to comments with RSS.
Comments have been closed for this post